
数据基数
数据基数
这是数据库建模者常用的术语,但业务用户并不太熟悉。理解这一点,它将解决你90%的数据问题。如果没有良好的数据模型,你必须处理Chasm和Fan Traps。
数据基数是关于在表格中维护细节水平的。数据基数有两种类型。
Ø高基数:当表中没有或很少有重复数据时,就称为高基数。具有主键的表通常处于最高基数模式。
Ø低基数:当表中有大量重复数据时,就称为低基数模式。带有外键的表通常处于低基数模式。
例如,产品表包含产品ID、产品名称和产品制造日期等详细信息。它可以包含数百种产品,但同时,特定的产品不能重复,因为它已经在表中了。因此,现在我们可以说这个表具有高基数。以同样的例子为例,如果有产品,那么必须也要销售。产品的销售可以存储在销售表中。现在,一种类型的产品可以被多次销售。因此,销售表可能包含数千行,其中数百行可能是针对某一个产品的,这意味着产品ID将在销售表中重复出现,因此我们可以说这个表相对于产品具有低基数性。
基数的度量有两个等级,分别是:
我们已经在另一个主题中讨论了数据建模,在那里我们将数据规范化到没有数据重复的程度。规范化的基本概念取决于基数。一旦我们将非规范化的表拆分成多个表以减少重复记录,主表将托管高基数数据,换句话说,成为主表,我们知道主表有Pkey(主键)。
所有的主键表都是高基数表,而Fkey(外键)表都是低基数表。
不要被表面现象迷惑,带有Fkey的表也可以有Pkey,并且可以成为另一个外键表的主表。因此,我们不能说所有Pkey表都具有绝对的最高基数。
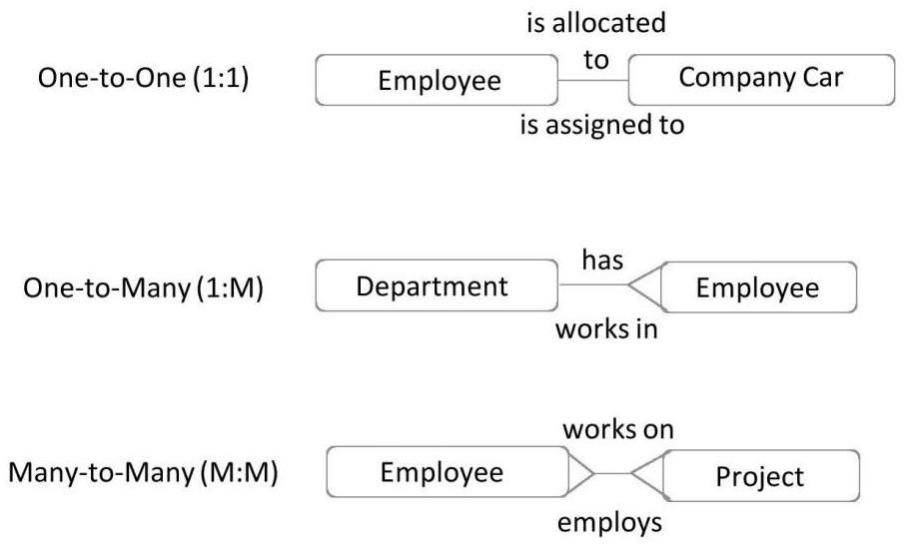
基数有三个类型。
Ø一对一(1:1):表A中的单行与表B中的单行相关联。
Ø一对多(1:M):表A中的单行与表B中的多行相关联。
Ø多对多(M:N):表A中的多行与表B中的多行相关联。
这个概念在没有使用Pkey和Fkey直接关系连接表格时也非常重要;使用错误的列进行连接可能会导致笛卡尔数据(在单独的主题中解释)。
了解基数在影响分析方面也非常重要。每当由于任何业务需求而更改表结构时,第一个问题应该问的是这种更改是否会影响任何表的基数。如果是,那么数据谱系将帮助你查看端到端的影响,为此必须进行元数据管理。

中心")


