
数据分级、分类和数据聚类
机器学习
分类分级
数据分级、分类和数据聚类
这两个术语在机器学习中用于数据挖掘和数据科学模型。众所周知,在机器学习中包括有监督学习和无监督学习方法。
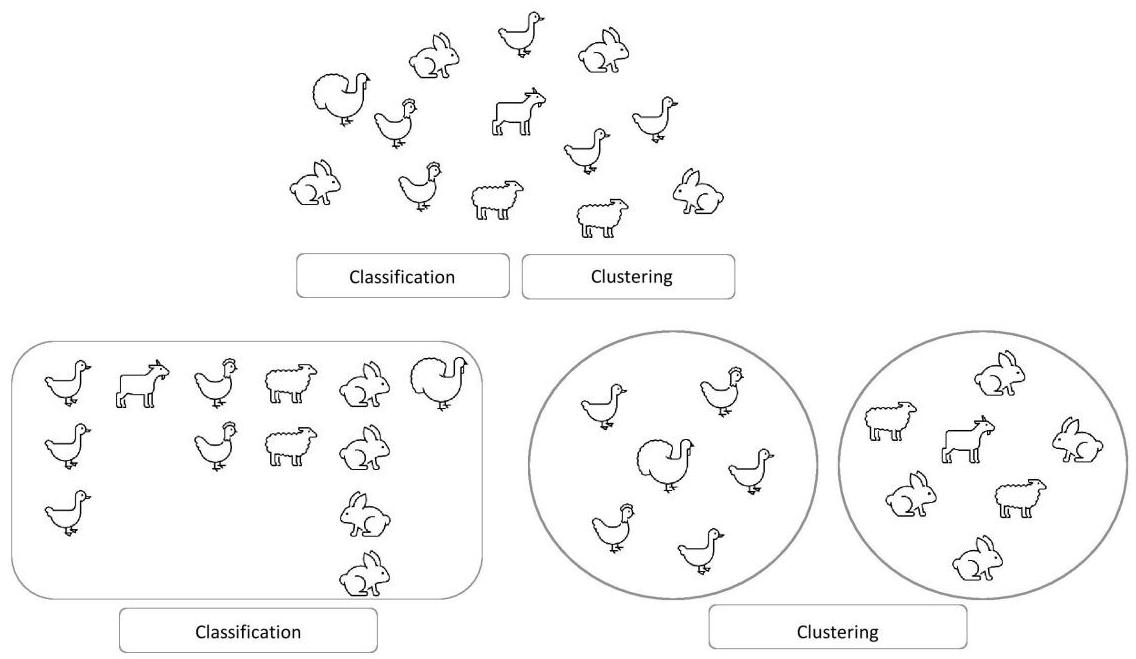
Ø数据分级/分类 = 有监督学习
Ø数据聚类 = 无监督学习
在复杂算法开始之前,这两个术语都用于模式识别。
分级/分类是根据数据的唯一性进行的,例如,所有动物都被单独标记,而聚类是根据特征完成的,例如,
1.有2条腿的动物
2.有4条腿的动物
Ø数据分级/分类使用标记数据,而数据聚类使用未标记数据。
Ø数据挖掘中最流行的数据分级/分类算法是K-最近邻和决策树算法。这两个术语在数据挖掘和数据科学中被广泛使用。
Ø数据挖掘中常见的两种数据聚类算法是K均值聚类和层次聚类。
Ø数据分级/分类输出是已知的。
Ø数据聚类输出是未知的。
Ø提供数据分级/分类的训练数据。
Ø未提供数据聚类的训练数据。
这两个术语在数据挖掘和数据科学中被广泛使用。

中心")



扫码联系
电话联系